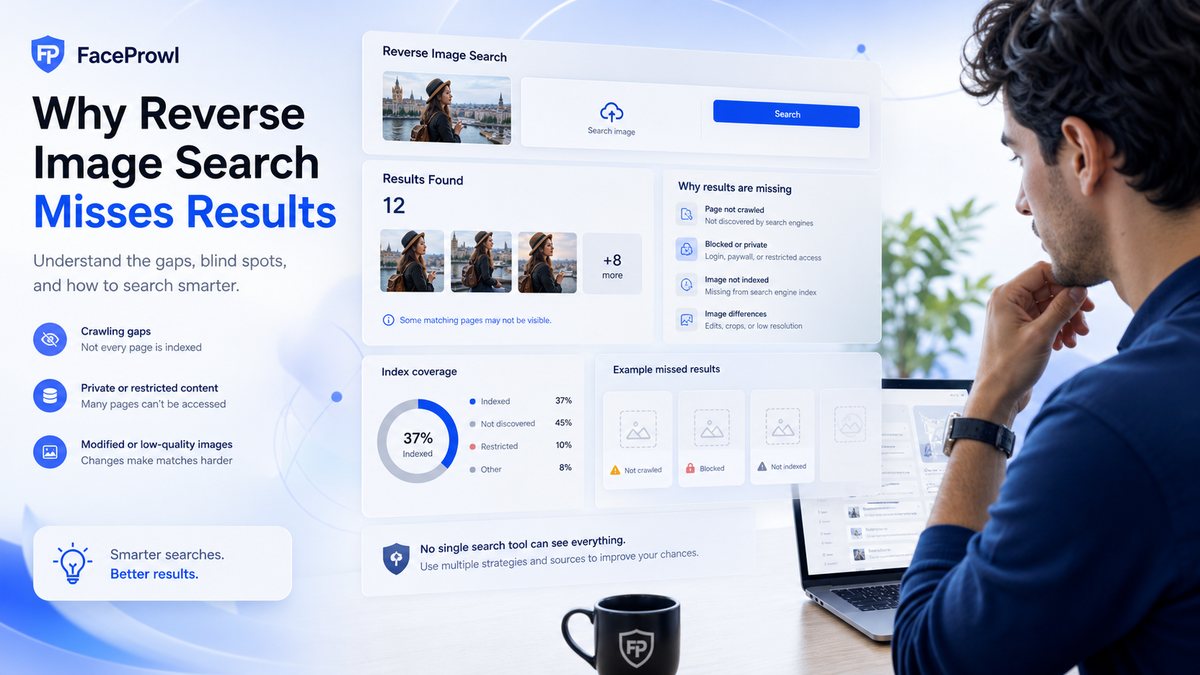
Why this matters
Why Reverse Image Search Misses Results is for users who expected more results from a search. The goal is a realistic explanation of coverage gaps and search limits while staying honest about limits. FaceProwl is designed around public-web source discovery, consent-based uploads, and reviewable URLs. It can help you organize a search, but the final decision should come from checking the page, image, and context together.
When people search for reverse image search misses results, they usually want a fast answer. A good search workflow should be fast, but it should also be careful. Public pages can change, indexes can miss new images, and similar faces or similar photos can create weak leads. The practical approach is to treat results as evidence to review, not as automatic proof.
The web is not one complete database
Search providers can only return pages they have crawled, indexed, and retained. Private pages, login-only profiles, blocked domains, and newly published images may be invisible.
Small changes can break exact matching
Cropping, overlays, compression, mirrored images, screenshots, and watermarks can make a copy harder to identify. Near-duplicate tools help, but they still have limits.
Repeat and diversify the search
Try more than one source photo, check again later, and compare exact image search with web detection. A missing result does not always mean the photo is not online.
Practical checklist
- Use photos you own or have permission to search.
- Choose clear images with enough face or subject detail.
- Review the source page before saving, sharing, or reporting a result.
- Keep the page URL, image URL, date, and screenshots when a result matters.
- Repeat important searches later because public web indexes change.
FaceProwl can help you search public-web source signals, preview possible matches, and unlock reviewable source URLs when a result is worth checking.
Start a FaceProwl searchFAQ
Can FaceProwl guarantee every matching page?
No. Public-web search depends on provider coverage, crawler permissions, page freshness, and whether images are accessible without login.
Should I treat a result as proof?
No. Treat a result as a lead. Review the page, image, domain, and context before taking action.